Today’s open source landscape features an ever-expanding number of mature projects with development activity spanning across multiple organizations. Developers on these projects come from large and small enterprises, educational institutions, and a pool of unaffiliated, open source developers. This diverse group of contributors work together to enable their projects’ core goals or use cases. However, with this diversity of projects, developers, and outcomes, there are challenges. How can we reliably meet the needs of all stakeholders? When setting up a continuous integration (CI) testing lab, it’s essential to build a framework that will allow the lab to handle incoming testing requests across diverse hardware and software platforms while providing a high-quality service. Without this, administering a CI testing lab can quickly become a whack-a-mole game of supporting ad-hoc testing requests that disrupt the speed and reliability of testing operations.
As testing administrators at IOL, we have learned from our challenges in building a CI testing lab for the Data Plane Development Kit (DPDK), an open source software project for high-speed packet processing. The DPDK developer community has worked with IOL over the years to build an effective and stable testing process. In this blog post, I will use the perspective of this project and the DPDK community to discuss how a CI testing lab can play the community testing role that an open source project requires.
Lesson #1 – Create A Communication Feedback Loop
To ensure that our testing services are reliable, relevant, and developed in good time, we maintain a short feedback loop between our testing lab and the developers of the open source community. Specifically, in DPDK, we meet with DPDK developers weekly, with topics alternating between test suite development, CI Lab infrastructure, and maintenance. Though it’s true the classic channel for communication in open source projects—the community mailing list—is an effective way of having conversations and one we also leverage, we find that holding regular meetings is essential for us to keep the CI community aligned with the project’s goals, objectives, and tasks. Regular meetings help us stay in sync on work progress and help resolve questions through group consensus from all CI testing participants. When done right, these meetings keep the CI project vibrant and in alignment with the community it serves.
Lesson #2 – Prioritize Completion of Testing and Re-Testing
Timely automated test reporting and community support is critical to the mission of a CI testing lab. For the CI testing lab to reduce the burden placed on software developers in an open source community, the lab must integrate well with the development, review, stage, and merge workflow used in the software project. In the DPDK Community Lab, we constantly deal with testing capacity considerations when standing up automated testing. This is often caused by time-consuming, end-to-end functional and performance testing on our finite inventory of HPC servers. Developers want to know if their patch is failing tests in minutes or hours, not a day or several days later. To provide timely feedback, we closely monitor the testing load on our DUT (device under test) systems to protect against excessive test queues, employ system and service monitoring tools such as Icinga to ensure DUT downtime is immediately flagged and addressed, and have developed a robust automated retesting system which allows us to re-queue dropped test runs in the event of a test infrastructure failure. When we have testing downtime, we make sure our team receives chat alerts immediately so we can investigate the issue and retesting can be triggered within an acceptable timeframe. Such timeliness and reliability allows software developers to focus more of their time on development and less on testing, thereby increasing their productivity. When working well, CI lab test results can act as an effective gating mechanism for patches, taking some of the workloads off of project maintainers and allowing them to allocate more time to their other duties.
Lesson #3 – Ensure Tests Can Be Recreated Locally
When standing up CI testing infrastructure, we are frequently tasked with deploying testing across a diverse set of hardware and software platforms. In the DPDK Community Lab, for instance, we run a broad set of build, unit, and end-to-end functional and performance tests across different CPU architectures, operating systems and Linux distributions, kernel versions, software stacks, and dedicated vendor hardware. It’s common for a test case to pass on most of our systems but fail on just one or two combinations of the many inputs above. When this happens, the next step is for the developer community to investigate the failure. This often involves an attempt on their part to recreate the test locally. So, how can a CI testing lab facilitate this? Well, we distribute the test suite logs as downloadable artifacts to the community, and also include system information and configuration with the test results we publish. Combined with good documentation for the relevant test suites being run, this should enable community members to re-run testing themselves. In cases where community members may not have the hardware necessary to recreate the test on their end, we may facilitate remote SSH access to our hardware for that individual or work with them to implement a manual retest according to their direction and share with them the results. For example, during the run-up to DPDK’s 24.03 release cycle, one of the major companies involved in DPDK submitted a patch that caused a failure on lab hardware that they could not reproduce at their own lab. Engineers from that company SSH accessed the IOL testbed that reported the failure and discovered that their patch was inadvertently initializing a capability on one of their NIC models where it was unsupported. Since our CI testing lab had this hardware, we caught the bug. Their patch was updated and merged into the main branch in time for the 24.03 release. By providing comprehensive system information alongside test reports, and by making our systems available to the community as needed, we enable the community to engage with our testing more constructively.
Lesson #4 – Automate Publishing of Timely Testing Coverage Reports
Producing code coverage reports indicates to an open source community what components of their project are being tested and how comprehensive (or not) the testing is. It is a good sign if patches being submitted to a project are passing CI testing, but if only half of the available modules in an open source project have tests written for them, that fact needs to be made clearly visible to the community! When we travelled to DPDK Summit 2023, we heard from community participants that this visual was needed to understand the current reach of testing and where our efforts needed to be directed next. This both clarifies to users of the project which components are well validated through testing, and encourages the community to work with lab maintainers towards improving testing code coverage where it is lacking. For the DPDK Community Lab, we now run 1x/month Lcov code coverage reports, which we post on our results dashboard.
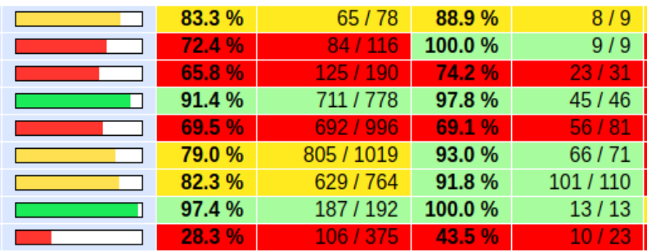
image: A partial view of the per library DPDK Code Coverage Report for September 2024
Lesson #5 – Integrate the Developer Community Into Test Suite Development
One lesson we’ve learned from DPDK is that test suite development should not happen as a side project handled by a few individuals at the lab. It must directly engage with and collaborate with the developers coming from the projects’ various stakeholders who are the primary actors contributing new features and updates. Using DPDK ethernet device tests as an example, we work with the community to write tests through a generic DPDK API, TestPMD (Test Poll Mode Drivers). This is an API that is supported by all the hardware vendor stakeholders in DPDK, so it’s an application the entire community is familiar with and able to work with in making test suite contributions. It also means the test suites we write can be used across hardware/software platforms, an important “nice to have” in the world of CI testing for open source projects. When paired with a good communication stream with the community—see Lesson #1—the outcome is a comprehensive body of test coverage.